
This is the last of three blog posts (for background and a description of typical issues see Part 1 with Part 2 describing typical solutions) that look at challenges with Word styles. This final part describes a standards-based approach that can be taken to check and normalize styles in a document (or batch of documents).
Part 3 – A standards-based solution
For many years the only way to do anything programmatically with a Word document was using the MS Word application itself. This was due to the flexibility and complexity of the application (therefore the underlying data) and the lack of a publicly published specification for the file format (.doc). Any solution to these issues had to be built on top of Word itself using macros, Word plug-ins or Word automation. As Word is a client-side tool, this means that all of these solutions needed to be deployed on client machines and would not operate on a server. Any business rules for styles and content would be included within the code of the application. This would then increase the complexity of roll-out of installation and especially of maintenance where templates are updated frequently.
In 2003 Microsoft created a public standard for an XML specification (Microsoft Office XML) that could be imported or exported from MS Word 2003. For the first time, developers could safely generate (or more easily adapt/transform) Word documents outside of the MS Word application. This allowed automation solutions to be developed for business challenges such as:
The single file format became a favorite for XML developers to transform via XSLT to whatever output was required but this approach was rarely adopted outside the publishing community or bespoke products.
Microsoft replaced that standard in later years with the ISO standard “Office Open XML” ultimately becoming the default read and write formats for MS Word (i.e. “.docx”). Docx files are basically a zipped set of folders containing XML files for the text, style, comments (plus graphics) required for a Word document. This new format allows developers to work directly with the core document format of MS Word but needs the developer to have the ability to “unpack” the files, update multiple files before repackaging as a “.docx”. This meant many XSLT developers (as XSLT cannot open ZIP files) stuck to the old format.
When developing a new standards-based solution for checking, reporting and fixing Word issues I turned to XProc. XProc is an XML language that allows users to define a “pipeline” of processing steps in a declarative way. XProc provides many built-in steps that can be combined together according to your needs that makes it perfect for processing Docx files. These steps include the ability to unzip, validate, compare, merge and manipulate XML, transform via XSLT and zip the results.
So, having dealt with the zipping and unzipping of documents, I needed a way to check the consistency and quality of the document style and content. While it is easy to validate the individual Word XML files against a schema (the “Office Open XML” schema) this only checks that the XML structure within the file matches what a Word document should have and does not check compliance against any business-specific rules such as style conformance or mandatory text content.
Fortunately, there is another way to check rules in an XML document that DOES allow such business-specific checks. Schematron allows a document analyst to define whatever simple or complex rules that is required to check the quality of a document and to provide information back to the business users on how to correct any issues. An example of a Schematron rule to test that a paragraph with a paragraph style “Heading 3” must be immediately preceded by a paragraph with style “Heading 2” is as follows.
<sch:rule context="cm:getThisParaStyle(.)='Heading3'">
<sch:assert test="cm:getParaBeforeStyle(.)='Heading2'" id="H3afterH2">Heading 3 must be immediately preceded by Heading 2</sch:assert>
</sch:rule>
As these rules are declarative and separate from any logic used to process the Word file itself, a document analyst is free to develop and maintain these rules without having to be an expert programmer. The Schematron format is an open standard with plenty of documentation and training guides on the web and it utilizes the XPath standard as the way to identify content in order to test its validity. I have also developed some simple helper functions such as “getThisParaStyle” in order to aid document analysts identify content without the need to have a deep understanding of the underlying Word XML format. These rules can check for the existence and validity of fields, metadata or that content of a certain type has text that fits a particular pattern (regular expressions). If required, a library of these tests can be created and re-used as required.
Once a document has been processed by the tool, the errors or warnings from Schematron are presented back to the user as Word comments with the location of the comment providing the context for the error. Users can utilize Word’s review toolbar to navigate their way through the comments.
Part 3 – A standards-based solution
For many years the only way to do anything programmatically with a Word document was using the MS Word application itself. This was due to the flexibility and complexity of the application (therefore the underlying data) and the lack of a publicly published specification for the file format (.doc). Any solution to these issues had to be built on top of Word itself using macros, Word plug-ins or Word automation. As Word is a client-side tool, this means that all of these solutions needed to be deployed on client machines and would not operate on a server. Any business rules for styles and content would be included within the code of the application. This would then increase the complexity of roll-out of installation and especially of maintenance where templates are updated frequently.
In 2003 Microsoft created a public standard for an XML specification (Microsoft Office XML) that could be imported or exported from MS Word 2003. For the first time, developers could safely generate (or more easily adapt/transform) Word documents outside of the MS Word application. This allowed automation solutions to be developed for business challenges such as:
- conversion from Word to XML for publishers;
- creation of customized contracts (with appropriate clauses inserted based-on information gathered) and whose style reflects the corporate Word template; and
- personalized reporting/marketing material (e.g. “your pension performance explained”).
The single file format became a favorite for XML developers to transform via XSLT to whatever output was required but this approach was rarely adopted outside the publishing community or bespoke products.
Microsoft replaced that standard in later years with the ISO standard “Office Open XML” ultimately becoming the default read and write formats for MS Word (i.e. “.docx”). Docx files are basically a zipped set of folders containing XML files for the text, style, comments (plus graphics) required for a Word document. This new format allows developers to work directly with the core document format of MS Word but needs the developer to have the ability to “unpack” the files, update multiple files before repackaging as a “.docx”. This meant many XSLT developers (as XSLT cannot open ZIP files) stuck to the old format.
When developing a new standards-based solution for checking, reporting and fixing Word issues I turned to XProc. XProc is an XML language that allows users to define a “pipeline” of processing steps in a declarative way. XProc provides many built-in steps that can be combined together according to your needs that makes it perfect for processing Docx files. These steps include the ability to unzip, validate, compare, merge and manipulate XML, transform via XSLT and zip the results.
So, having dealt with the zipping and unzipping of documents, I needed a way to check the consistency and quality of the document style and content. While it is easy to validate the individual Word XML files against a schema (the “Office Open XML” schema) this only checks that the XML structure within the file matches what a Word document should have and does not check compliance against any business-specific rules such as style conformance or mandatory text content.
Fortunately, there is another way to check rules in an XML document that DOES allow such business-specific checks. Schematron allows a document analyst to define whatever simple or complex rules that is required to check the quality of a document and to provide information back to the business users on how to correct any issues. An example of a Schematron rule to test that a paragraph with a paragraph style “Heading 3” must be immediately preceded by a paragraph with style “Heading 2” is as follows.
<sch:rule context="cm:getThisParaStyle(.)='Heading3'">
<sch:assert test="cm:getParaBeforeStyle(.)='Heading2'" id="H3afterH2">Heading 3 must be immediately preceded by Heading 2</sch:assert>
</sch:rule>
As these rules are declarative and separate from any logic used to process the Word file itself, a document analyst is free to develop and maintain these rules without having to be an expert programmer. The Schematron format is an open standard with plenty of documentation and training guides on the web and it utilizes the XPath standard as the way to identify content in order to test its validity. I have also developed some simple helper functions such as “getThisParaStyle” in order to aid document analysts identify content without the need to have a deep understanding of the underlying Word XML format. These rules can check for the existence and validity of fields, metadata or that content of a certain type has text that fits a particular pattern (regular expressions). If required, a library of these tests can be created and re-used as required.
Once a document has been processed by the tool, the errors or warnings from Schematron are presented back to the user as Word comments with the location of the comment providing the context for the error. Users can utilize Word’s review toolbar to navigate their way through the comments.
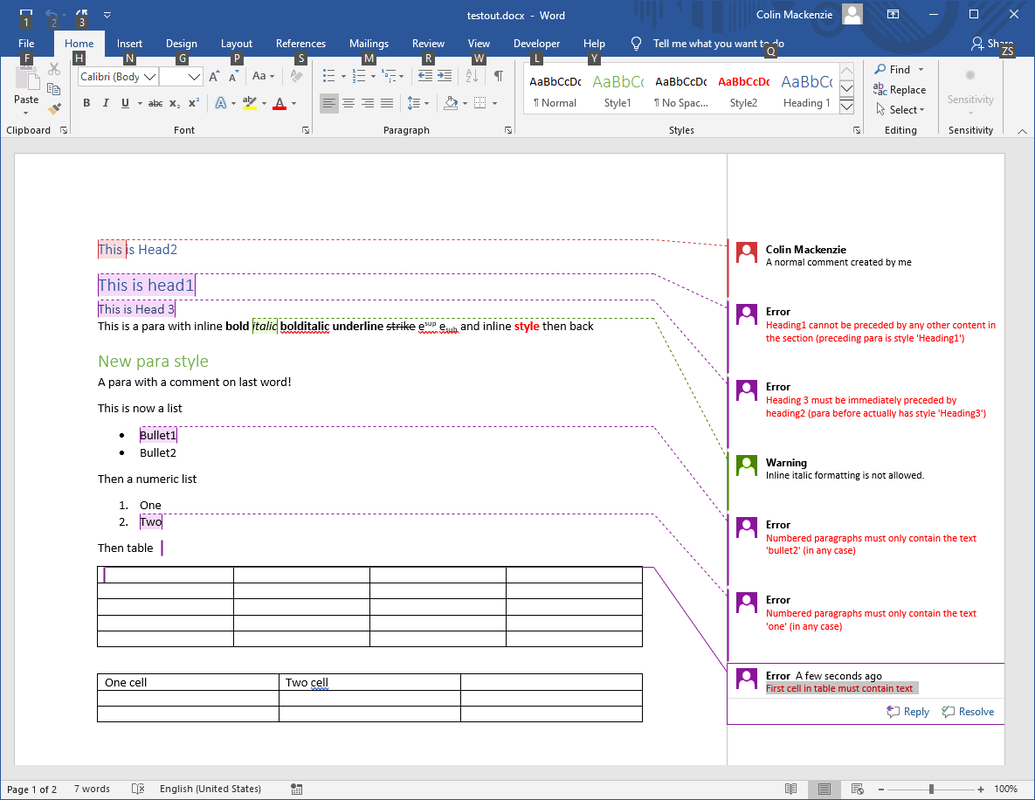
Once a user remedies the issue (e.g. by changing style to the correct style or by moving an existing paragraph into the correct position) the file can be reprocessed allowing the existing errors/warnings to be stripped and any new or remaining issues to be created as new comments.
This is not the first solution to suggest using Schematron with Office documents (with feedback as comments) for this purpose (see Andrew Sales presentation at XML London) but I have tried to push the concept further:
The XProc process also supports recording the quality of the document to be logged in an XML log file so that an entire library of documents can be checked for style conformance (especially important for beginning some new project that presumes consistency of content). The log can be queried or transformed (e.g. for loading into Excel) to provide business intelligence on a batch of documents.
<log date="2019-11-12">
<entry stylesMatch="true"
errorCount="5"
warnCount="1"
issues="H1notfirst H3afterH2 Bullet2 NumOne FirstCelltext"
warnings="NoI"
filename="test.docx"
startDateTime="2019-11-12T16:37:49.614Z"
endDateTime="2019-11-12T16:37:49.621Z"/>
This XProc process could be invoked in a number of ways depending on the business requirement and IT limitations:
Final thoughts:
I will keep working on this solution to provide additional features (such as a way to allow users to select from a number of possible fixes) and to develop a library of functions to make development of rules and fixes easier. I hope to present the solution at an XML conference next year.
If you have any use cases you would like to suggest, any questions you would like to raise or if your company would like to use this approach and engage my services, please get in touch.
This is not the first solution to suggest using Schematron with Office documents (with feedback as comments) for this purpose (see Andrew Sales presentation at XML London) but I have tried to push the concept further:
- Focusing on business cases other than those of supporting XML conversion from Word.
- Enhancing the usability of the feedback provided to the users.
- Performing the checks on native .docx files.
- Detecting the type of document and selecting the correct Schematron rule files to use to check that file (therefore supporting general rules, corporate rules and template/content specific rules).
- Checking that the styles used in the document matches those in a reference master style file.
- Provide options to strip existing user generated comments (important before final delivery of a document) or to keep those comments.
- Where fixes can be automated, run fixes in XSLT steps prior to checking quality.
The XProc process also supports recording the quality of the document to be logged in an XML log file so that an entire library of documents can be checked for style conformance (especially important for beginning some new project that presumes consistency of content). The log can be queried or transformed (e.g. for loading into Excel) to provide business intelligence on a batch of documents.
<log date="2019-11-12">
<entry stylesMatch="true"
errorCount="5"
warnCount="1"
issues="H1notfirst H3afterH2 Bullet2 NumOne FirstCelltext"
warnings="NoI"
filename="test.docx"
startDateTime="2019-11-12T16:37:49.614Z"
endDateTime="2019-11-12T16:37:49.621Z"/>
This XProc process could be invoked in a number of ways depending on the business requirement and IT limitations:
- Run on current Word file from custom macro in Word (client side or posted to a server application).
- Invoked from a workflow, content management or publishing solution as part of a “check” stage using Java or by running a BAT file.
- Run from PowerShell when a file arrives in a specific network folder.
- Run from a Bat file on a hierarchical folder full of Word files.
- Run from XML processing tolls such as Oxygen.
Final thoughts:
- It is perfectly possible to achieve much of the same functionality in C# or VB .Net (especially using the Open XML SDK) but developing using open standards inspires us to think of new standard-based approaches that can deliver real business benefits (such as having declarative rules in Schematron and not spaghetti rules embedded in impenetrable code).
- Without a well-thought-out Word template, it is not really possible to infer or validate styles.
- While it is possible to automate some fixes (e.g. swapping out-of-date style names to new ones or selecting a more modern template) manual intervention will be required where content is missing or needs human intervention in order to decide how best to rearrange it.
- Where you need to capture complex semantic information, you have difficult publishing requirements or you want to take advantage of component-based re-use and translation then you should consider authoring using an XML editor with schema and Schematron validation performed at source.
I will keep working on this solution to provide additional features (such as a way to allow users to select from a number of possible fixes) and to develop a library of functions to make development of rules and fixes easier. I hope to present the solution at an XML conference next year.
If you have any use cases you would like to suggest, any questions you would like to raise or if your company would like to use this approach and engage my services, please get in touch.
 RSS Feed
RSS Feed